
Anzeige

Nachdem wir ja bereits einen Artikel über das neue DaVinci 20 veröffentlicht haben, gucke ich mir in diesem ein paar der neuen oder überarbeiteten KI-Funktionen im DaVinci Studio an. Derer sind so viele dazugekommen, dass man bei einer detaillierten Beschreibung auf eine im Umfang einem Handbuch ähnliche Seitenanzahl kommen würde.
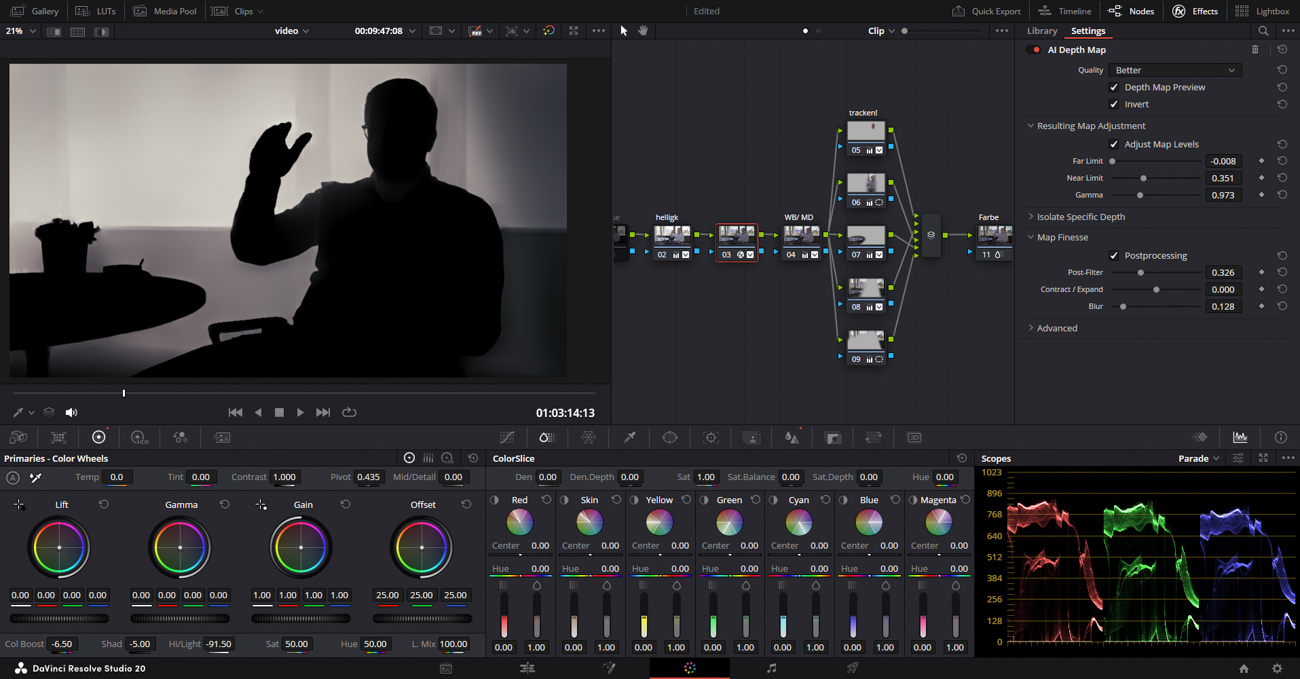
Ganz speziell geht es in diesem Artikel um den »Cinematic Haze« in Verbindung mit der neuen Depth Map und die »AI Magic Mask 2«. Mit diesen beiden Tools lässt sich – eine gute Grafikkarte vorausgesetzt – ziemlich schnell ziemlich viel »Production Value« in Videos bringen.
KI-Funktionen in DaVinci
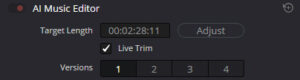
AI Music Editor.
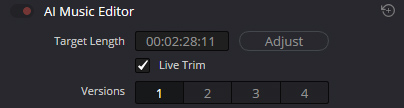
Zunächst aber ein kurzer Ausflug in die KI-Funktionen von DaVinci. Worauf viele gewartet haben, ist der seit einiger Zeit implementierte »AI Music Editor«.
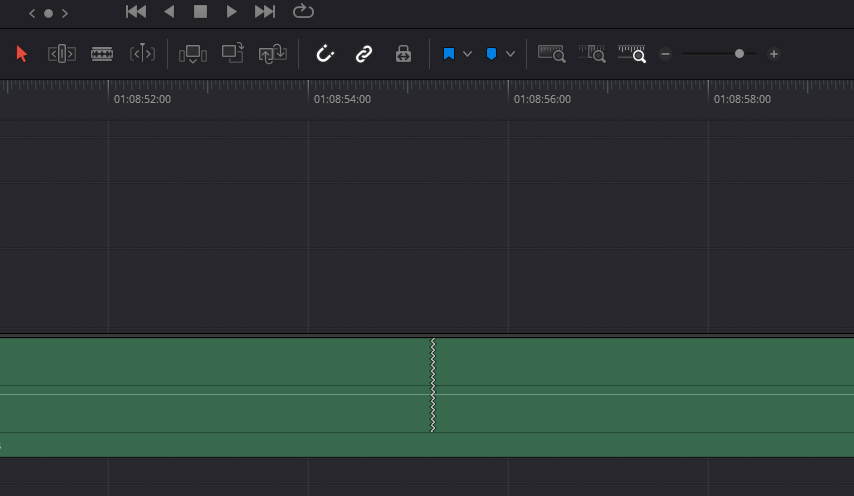
AI Music Editor Cut in Timeline.
Ziel ist es, das Musikstück mit dieser Funktion zu verlängern oder zu verkürzen, damit der Track von der Länge her zum Video passt. Dazu analysiert die KI die Musik und fügt an passenden Stellen Übergänge ein.
Wenn man ein bisschen darauf achtet, dass aus vier Takten nicht plötzlich drei werden, ist das eine extrem praktische Sache.
Der »AI Dialog Matcher« überträgt die Audioeigenschaften von einem Interview auf ein anderes und matcht dabei die Lautstärke, den Ton und die Atmosphäre. Man kann über Clip / Audio Operations die EQ- und Level-Werte kopieren und einfügen.
Das funktioniert so gut, dass der Ausgangston am besten ideal ausgepegelt und abgestimmt sein sollte, denn es werden auch kleinere »Fehler« kopiert: Ist der Ausgangsclip übersteuert, hört auch der veränderte sich so an.
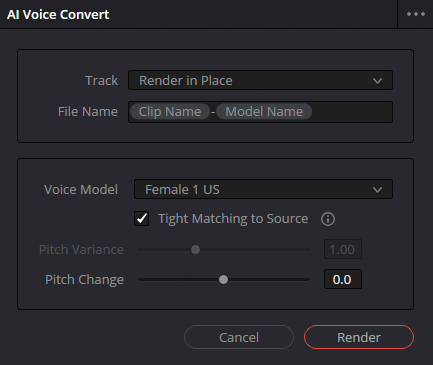
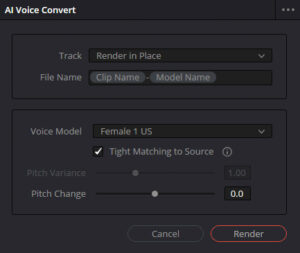
AI Voice Convert.
»AI Voice Convert« erstellt ein Soundmodell aus einer Stimme.
Das kann in der Praxis zum Beispiel so funktionieren: Ein Interviewpartner verspricht sich oder man kürzt das Interview so sehr ein, dass einem Worte fehlen und man nicht 20 Minuten Material etwa nach einem »das« in passender Stimmlage durchsuchen will. Jetzt lässt man im Idealfall zehn Minuten der Stimme des Interviewpartners analysieren, spricht die fehlenden Worte selbst ein (dabei ist es nicht wichtig, dies an derselben Location zu tun) und ändert seine Stimme über Clip / AI Tools / Voice Convert in die des Gesprächspartners. Das funktioniert natürlich nur, solange dieser nicht im Bild ist.
Seite 1: Einleitung
Seite 2: Cinematic Haze
Seite 3: Depth Map, AI Magic Mask 2

Anzeige






Anzeige

Anzeige

Anzeige

Anzeige
