
Anzeige






Anwendungslandschaften
Der zunehmende Kostendruck in der Broadcast-Branche führt zu einem hohen Rationalisierungsbedarf in Bezug auf die Arbeitsabläufe: Die Anwender akzeptieren es aus Kostengründen nicht mehr, wenn sie bestimmte Informationen mehrfach eingeben oder einzelne Elemente und Informationen eines Sendebeitrags aus verschiedenen Systemen zusammensuchen müssen. Übergreifende Arbeitsabläufe, und nicht mehr die Einzelfunktion wie etwa der Schnitt, rücken damit bei den Broadcastern in den Fokus der Aufmerksamkeit. Das erzwingt eine horizontale Strukturierung, wie sie in reinen IT-Anwendungen bereits vor Jahren stattgefunden hat. Von der Anwenderseite getrieben, fügen sich die Broadcast-Hersteller allmählich diesem Trend – wenn auch ohne große Begeisterung.
Entlang der Wertschöpfungskette im Broadcast-Markt treten daher Anwendungen auf, die
aus unterschiedlichen Software-Generationen stammen
einen unterschiedlichen Wartungsstand haben
immer stärker miteinander vernetzt sind.
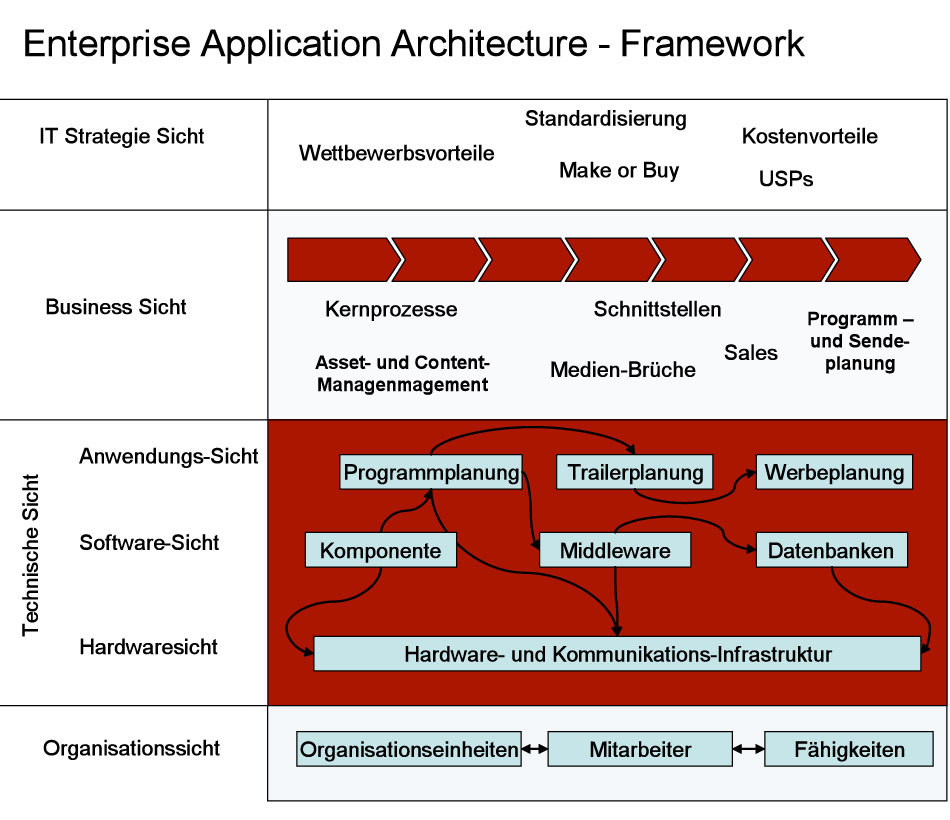
Die Liste von Kriterien, nach denen sich die Anwendungen strukturiert erfassen lassen, ist lang und fast beliebig erweiterbar. Letztlich muss jedes Unternehmen für sich selbst die fünf bis zehn wesentlichen Kriterien bestimmen, nach denen es seine Anwendungen erfassen will. Wie so eine Strukturierung aussehen kann, zeigt das Beispiel von ProSiebenSat1, das Flying Eye im Rahmen eines Restrukturierungsprojektes vorgeschlagen hat: Abbildung 3 zeigt den Blick aus unterschiedlichen Perspektiven auf die Software-Landschaft, die natürlich je nach Fragestellung differieren.
Entscheidungen dürfen dabei eben nicht nur auf Basis einer Sichtweise fallen, sondern es gilt, das »große Ganze« zumindest im Auge zu behalten und einen übergeordneten Blick auf die Anwendungslandschaft zu bekommen. Die Entscheider haben damit eine Basis, um bei knapper werdenden Budgets priorisieren zu können. Außerdem werden sofort elementare Strukturdefizite sichtbar — etwa das Fehlen einer zentralen, einheitlichen Material-ID. Auch die »trojanischen Pferde« lassen sich damit eindämmen: Anforderungen, die von einer der beteiligten Seiten druckvoll eingefordert werden, deren Zweck aber nicht die Optimierung der Prozesse ist, sondern die Sicherung von Machtpositionen.
Solche Ansätze erfordern vor allem in der Anfangsphase einen gesunden Pragmatismus, damit sie nicht ausufern und einen Aufwand verlangen, dem kein entsprechender Erkenntnisgewinn entgegensteht. Spezialisten aus vielen Bereichen, die ihre Prozesse gut kennen, müssen hierbei einbezogen werden, es gilt aber große, träge Gremienorganisationen zu vermeiden. Eine Stabsstelle und Workshops mit den Spezialisten aus den Abteilungen/Bereichen ist meist die richtige Herangehensweise.
Havarie-Konzepte
Bisher stützt sich der Broadcast-Betrieb insbesondere in den sendenahen Bereichen, etwa der Live-Regie oder der Sendeabwicklung, auf stark hardware-lastige Havarie-Konzepte. Die »harte Bank« in einer Live-Regie — ein hardware-basiertes Notsystem mit Standalone-Geräten — ist dafür ein gutes Beispiel. Was nutzt allerdings diese harte Bank, wenn kurz vor den 20:00-Uhr-Nachrichten das Netzwerk ausfällt und auf der harten Bank lediglich der Moderator vor grünem Hintergrund geschaltet werden kann, weil die Rechner des virtuellen Systems auch am Netzwerk hängen? Einfache Maßnahmen, wie etwa ein Nachrichten-Aufsteller und einige vorab ausgespielte Beiträge, die auf einem separaten Server gespeichert sind, können eine solche Situation viel eher retten. »Das ist zu einfach gedacht«, mag der eine oder andere einwenden, aber die Alternative sind heutzutage eben sehr, sehr teure Redundanzen in Hard- und Software.
Der oben beschrieben Fall zeigt auch einen anderen Aspekt auf: In Zeiten integrierter IT-Broadcast-Systeme muss den Schnittstellen zwischen den Systemen besondere Aufmerksamkeit gewidmet werden.
Zu Fragen der Hard- und Software-Redundanzen kommen weitere hinzu: Welche Abläufe und Prozesse müssen im Havariefall in Gang kommen? Wie werden diese beim Personal geschult? Havarie-Trainings, wie sie bei Flugzeugpiloten üblich sind, werden mit Regiebesetzungen eher selten durchgeführt. Stattdessen gibt es oft genug erst Diskussionen, nachdem es »geknallt« hat: Warum wurden die für diesen Fall vorgesehenen Maßnahmen nicht ergriffen? Auch für die oben vorgeschlagenen einfachen Havarie-Maßnahmen gilt das: Wenn der Operator das Havarieband nicht findet oder es an diesem Tag gerade mal nicht ausgespielt wurde, helfen alle Havarieplanungen nichts.
Störungs-Management
Wer diese Situation nicht kennt, der kann sie sich zweifellos leicht vorstellen: Der Prompter-Rechner in der Regie funktioniert nicht mehr und schon geht es los, das berühmte Support-Ping-Pong: »Die Anwendung hat sich aufgehängt!« – »Nein, bei mir läuft alles, es muss die Datenbank sein!« – »Nein, die Datenbank läuft, liegt’s vielleicht am Netzwerk?« – »Quatsch, das Ding bekommt überhaupt keine Daten von Redaktionssystem.« In dieser Art kann der Dialog über mehrere Schleifen weitergehen. Ein Anruf bei der Hotline führte nur ins Call-Center in Ungarn, von wo erst einmal die Inventar-Nummer des Rechners angefordert wurde, damit man ein Ticket eröffnen kann: schiere Verzweiflung in der Regie.
Wie lassen sich solche Szenarien ausschließen? Grundsätzlich erfordern Systeme, die nahe an den Live-Strecken liegen, eigene, wesentlich höher priorisierte Meldewege. Hierfür gibt es mehrere Möglichkeiten: So könnte man Anrufe von bestimmten Telefonapparaten automatisch zu bestimmten Spezialisten leiten, aber auch ein manuelles Call-Routing kann eine Alternative sein.
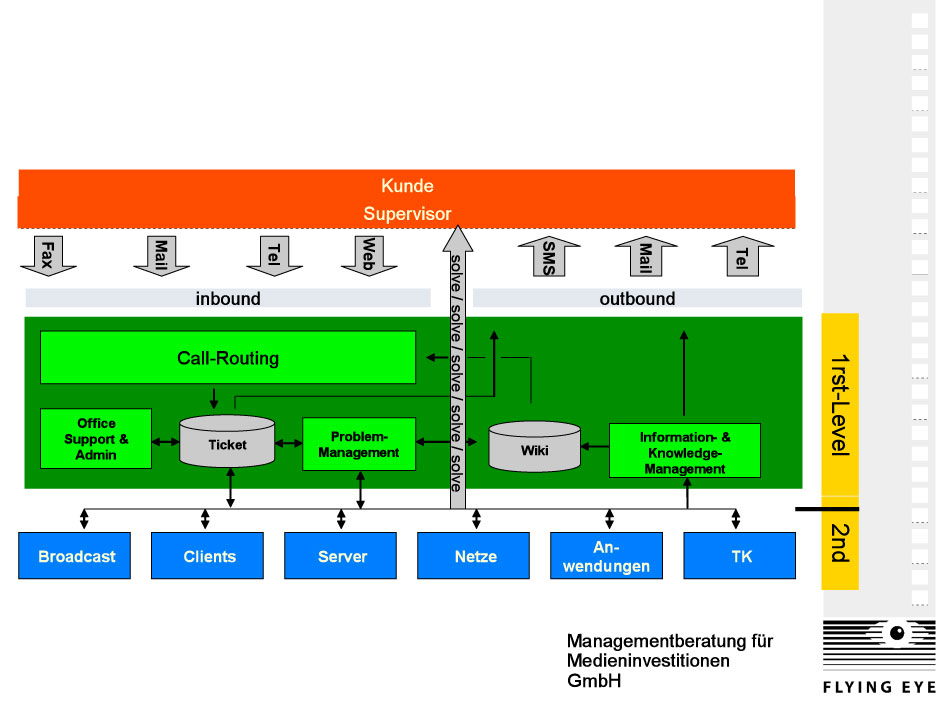
Grafik II veranschaulicht das Zusammenspiel der verschiedenen Werkzeuge und Kommunikationswege in einem Supportprozess, mit dem sich ein effizientes Störungsmanagement realisieren lässt.
Ein weiterer Aspekt im Störungsmanagement ist der Umgang mit Wissen. Allrounder, die nach kurzem Nachdenken im Störungsfall eine Lösung bieten können, sind längst die Ausnahme: Dedizierte IT und allgemeine IT bedürfen bei Problemen eines so hohen Detailwissens, dass dies ein einzelner Mitarbeiter gar nicht mehr abdecken kann. Künftig werden aber die Budgets nicht mehr reichen, um viele Spezialisten zu beschäftigen, und die Mahnung »Lass bloss dein Handy an«, wird auf die Dauer auch nicht helfen.
Es gibt noch weitere Aspekte: Damit der stark beanspruchte Service-Mitarbeiter überhaupt weiß, welche Systeme genau mit diesem einen Prompter verknüpft sind, benötigt man eine Wissensbasis: Wiki-Systeme eignen sich hervorragend, um das Wissen über die Anwendungen und ihre Vernetzung zu speichern. Sie bieten eine einfache Möglichkeit, die notwendige Aktualität der Information durch die Produktverantwortlichen zu erhalten. Definiert man klare Systemverantwortungen, lassen sich darüber auch notwendige Veränderungen (Issue und Change) einfacher steuern.
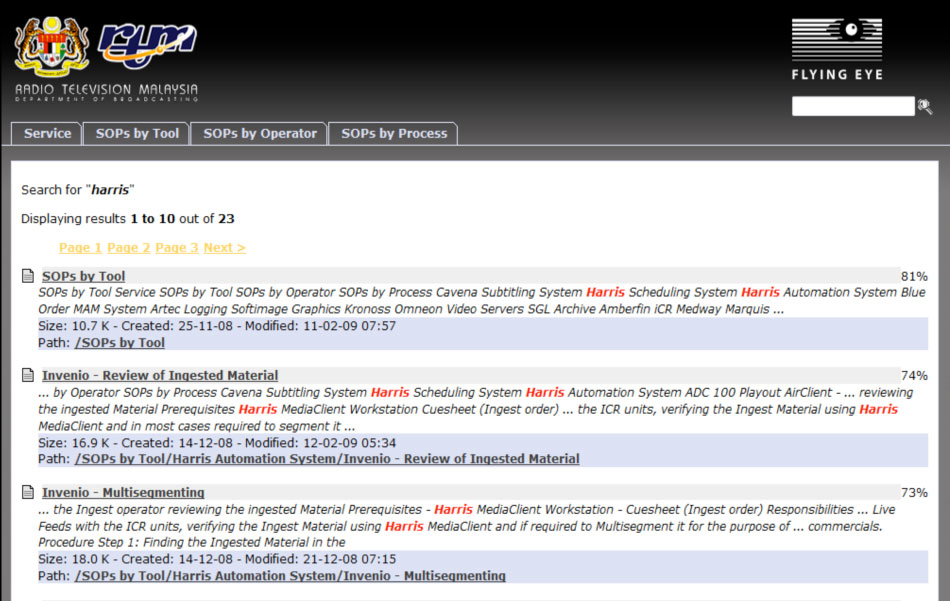
Um Störungen strukturiert beheben zu können, die Kommunikation mit dem genervten User zu optimieren, und sicherzustellen, dass man aus Fehlern lernt, ist ein Ticket-Tool für das Incident-Management notwendig, selbst oder sogar gerade bei kleineren Organisationen. Flying Eye hat etwa auf Basis einer günstigen Standardlösung ein solches Tool bei RTM in Malaysia eingeführt (siehe Screenshot) und den Auswahlprozess für ein solches System auch bei ProSiebenSat1 begleitet. Sind Wissens-Datenbank mit Konfigurationsdaten und das Ticket-Tool eng verzahnt, steht dem reibungslosen Betrieb nichts mehr im Weg.
Dienstleistungsstrukturen
Dienstleistungsstrukturen sind häufig vertikal strukturiert: Auf der einen Seite gibt es den sogenannten Broadcast-Support sowie die Mess- oder Systemtechnik, auf der anderen Seite den IT-Support, in dessen Aufgabenbereich ein breites Spektrum fällt, das von Office-Applikationen über Datenbanken bis hin zu Planung und Betrieb der Rechenzentren reicht. Beim heutigen Stand der Technik ergibt es aber keinen Sinn mehr, hier unterschiedliche Strukturen aufrecht zu erhalten: Die verschiedenen Anwendungen wachsen entlang der Arbeitsabläufe zusammen, daher müssen auch die Service-Funktionen viel enger zusammenarbeiten.
Dies wird von zwei aktuellen Entwicklungen flankiert: Beginnend von der Hardware-Seite bis hin zur hardware-nahen Software hat eine gewisse Standardisierung eingesetzt, so wird versucht, die Menge an notwendigem Know-how zu begrenzen. Letztlich gleichen sich zudem auch die eingesetzten Werkzeuge immer mehr an. Es spricht also vieles dafür, Service-Funktionen strukturell zusammenzulegen.
IT-Experten lernen in einem solchen interdisziplinären Austausch, weshalb nicht die Sanduhr auf dem Bildschirm erscheinen darf, wenn der Operator am Bildmischer um 20:00 Uhr auf die Take-Taste drückt. Hartgesottene Broadcast-Techniker erkennen, dass es bereits viele geeignete Werkzeuge gibt, um die schöne neue Technikwelt zu überwachen.
Dieser Umbruch offenbart noch ein weiteres Thema: Die Frage der Quantität und Qualität des Personals.
Die oben angedeutete Vernetzung der Systeme erhöht deutlich die Notwendigkeit, in Support-Organisationen Mitarbeiter mit Systemüberblick einzusetzen. Diese Rolle unterscheidet sich deutlich von der eines Produktspezialisten, der üblicherweise ein hohes Spezialwissen zu einer Anwendung hat. Die Systemspezialisten sind diejenigen, die das Support-Ping-Pong im Keim ersticken müssen. Vielleicht erlebt ja der IvD (in Kombination mit den Fähigkeiten eines AvD ) eine gewisse Renaissance.
Durch den Kostendruck und die Tatsache, dass entgegen aller Ankündigungen noch für eine lange Zeit in der Praxis ein Parallelbetrieb verschiedener Technologien die Realität darstellen wird, entsteht ein strukturelles Defizit an Ressourcen im Bereich des technischen Betriebs. Hier offenbart sich eine weitere grundlegende Frage: Was genau zählt zum technischen Betrieb? Bei der heutigen Definition von Produktion und Technik in Rundfunkanstalten geht die Trennungslinie mitten durch gewachsene Strukturen. Ist der Cutter, der einen Schnittplatz hochfährt, schon Administrator?
Gleichzeitig soll sich das ohnehin schon reduzierte Personal nicht nur auf andere Technik einstellen, sondern auch auf völlig andere Geschäftsprozesse des IT-Service-Managements. Die verbliebenen und wenigen Mitarbeiter müssen sich also auch noch massiv fortbilden. Ein Aufgabe, die vermutlich nur einige wenige Hochmotivierte bewältigen werden. Intelligente und kreative Lösungen wie etwa bei einer Kombination aus gegenseitigem Training-on-the Job, modernen Werkzeugen und Rufbereitschaften, können hier Kapazitäten schaffen, um die »Lass-dein-Handy-an«-Organisation abzulösen.
Outsourcing
Ausgelöst durch den hohen Investitionsdruck beim Einsatz von IT und unter dem Gesichtspunkt der Kostentransparenz und Kosteneinsparung wird auch die Broadcast-Branche in den nächsten Jahren nicht um die Fragestellung herumkommen, ob die Anschaffung und der Betrieb von IT-Systemen zur Kernkompetenz von Broadcastern gehören. Das spült ein brisantes Thema an die Oberfläche: Outsourcing.
Die Erfahrungen mit ersten Versuchen in der Branche zeigen nicht die gewünschten Ergebnisse. So wurden interne Abteilungen einfach ausgegliedert, aber die erwarteten Optimierungsgewinne konnten nicht realisiert werden. Gründe dafür sind das berechtigte Interesse der Lieferanten, ihre Marge zu erwirtschaften, aber auch ihr mangelndes Verständnis der wertschöpfenden Abläufe. Der reale oder manchmal vielleicht auch nur gefühlte Service-Level geht dramatisch zurück oder es kommt zu erheblichen Nachforderungen der Dienstleister.
Beim Outsourcing ist positiv zu bewerten, dass es zu einer Zwangsstandardisierung der Technik und der Abläufe kommt, die aufgrund unternehmensinterner Machtpolitik sonst nur schwer und langwierig zu erreichen wäre. Auch die oben angesprochenen »Trojaner-Effekte« gehören dann der Vergangenheit an.
Um das Outsourcing erfolgreich zu gestalten, ergeben sich aus Sicht von Flying Eye wesentliche Fragestellungen, von denen hier nur einige plakativ angerissen werden sollen:
Welche der Teile der IT sind vielleicht doch Kernkompetenz und eigenen sich deshalb nicht für ein Outsourcing?
Was muss zunächst in der eigenen Organisation, insbesondere der Ablauforganisation geschehen, um optimal auf das Outsourcing vorbereitet zu sein?
Sind die eigenen Kosten der Prozesse, die zur Diskussion stehen, in ausreichender Detaillierung bekannt?
Sind die Schnittstellen zu den zukünftigen Auftraggebern und Leistungsempfängern eindeutig definierbar?
Welche Leistungsanreize können dem Dienstleister gestellt werden?
Welche Auswahlkriterien sollte man bei der Suche nach dem richtigen Dienstleister anlegen?
Wie offen oder restriktiv sollten Service-Level-Agreements gestaltet werden?
Welches sind die korrekten Messgrößen zur Überprüfung der Service-Level-Agreements (SLA)?
Beachtet man all dies, sind die Kostenvorteile des Outsourcings für bestimmte Bereiche nicht weg zu diskutieren. All diese Überlegungen gelten natürlich auch dann, wenn schon Erfahrungen mit Outsourcing gemacht wurden: In der Regel lohnt es sich, Verträge bezüglich der Service-Level und der Preise nachzuverhandeln, um das Outsourcing zu optimieren.
In letzter Zeit macht auch das Schlagwort »Managed Services« die Runde. Für klar abgrenzbare Geschäftsprozesse ist dies sicher denkbar. Versucht man allerdings, komplexe, hochintegrierte Geschäftsprozesse mit zahlreichen Schnittstellen zu anderen Anwendungen darin unterzubringen, wird es sehr schwierig, den Service-Level zu festzulegen.
Fazit
Die Anwendungslandschaften in Broadcast-Unternehmen sind mittlerweile so komplex, dass sich klassische Organisationsformen nicht mehr aufrecht erhalten lassen. Die Nähe zu den Live-Produktionsketten und das Spannungsfeld zwischen Systemüberblick einerseits und tiefem Produkt-Knowhow der Spezialisten andererseits sollten Kriterien für neue Organisationsformen sein. Dies gilt sowohl für die Ablauf- wie auch für die Aufbauorganisation.
Auch Outsourcing, als vermeintlich einfache Lösung, in der viele Manager die schnelle Lösung sehen, ist mit Aufwand verbunden. Ganze Organisationen auf IT-Service-Level-Management umzustellen, ist keineswegs zum Nulltarif möglich. Investiert man diesen — meist internen — Aufwand aber nicht, droht einer der vielen Fälle, die Outsourcing in bestimmten Bereichen in Verruf gebracht haben.
Aus all diesen Erfahrungen hat sich mit den Jahren in anderen Industrien ein Best-Practice-Framework herauskristallisiert, das sich ITIL nennt. Es steht für IT Infrastructure Library und sieht sich als De-facto-Standard im Bereich Service-Management. ITIL bietet eine umfassende Dokumentation zur Planung, Erbringung und Unterstützung von IT-Serviceleistungen. Manchmal lohnt sich ein Blick über den Tellerrand, um zu erkennen, dass wir in der Broadcast-Branche nicht alle Erfahrungen selbst machen müssen.





Anzeige






Anzeige

Anzeige

Anzeige

Anzeige
