
Anzeige

Audio
Ein sehr gutes Beispiel für KI in diversen Belangen ist die Audiobereinigung.
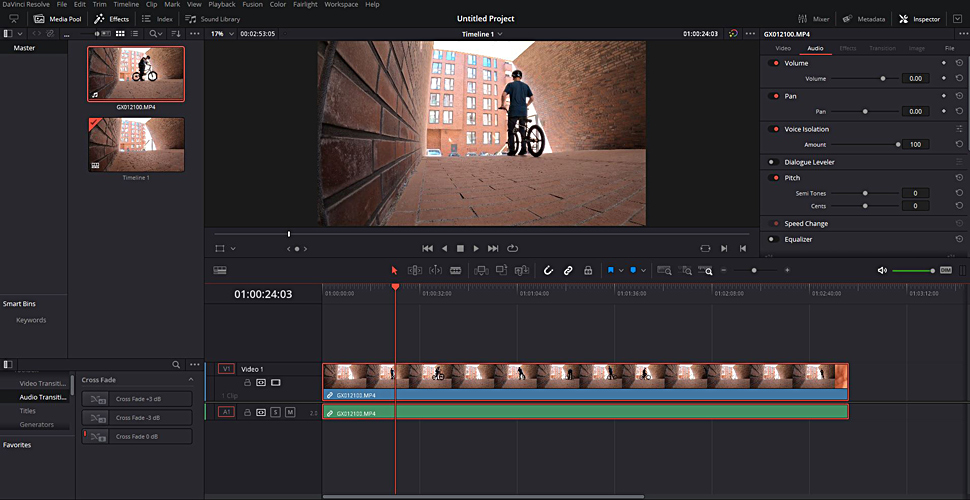
Schon früh in DaVinci Resolve implementiert: das Tool »Voice Isolation«.
Blackmagic etwa hat ja schon sehr früh angefangen, KI in diesem Bereich in DaVinci Resolve einzubauen. So war unter anderem relativ früh schon das Tool »Voice Isolation« implementiert.
Dieses Tool isoliert eine Stimme und entfernt Hintergrundgeräusche wie Rauschen und alles andere Unliebsame aus der Tonspur.
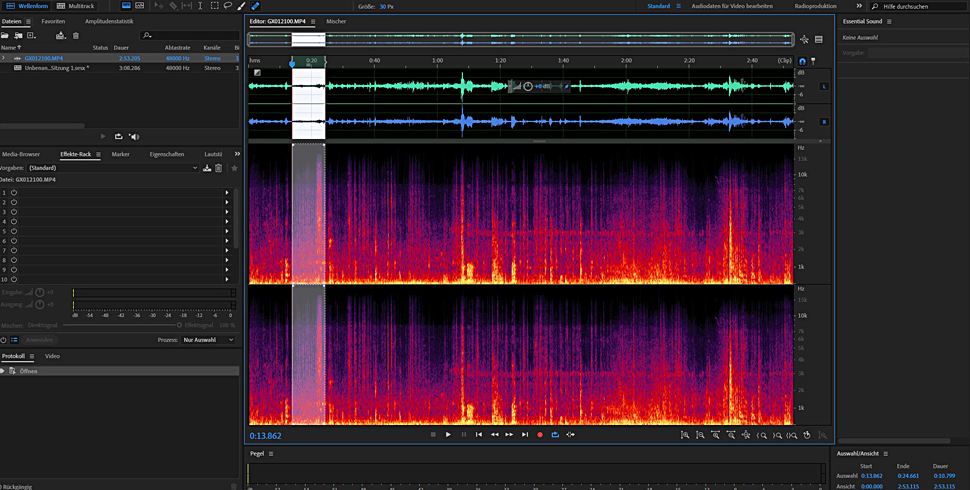
Am besten funktioniert die Rauschreduktion, wenn man eine Audiostelle hat, an der nur das Rauschen zu hören ist.
Um diese KI-Funktion zu verstehen, vergleichen wir sie einfach mal mit bisherigen Rauschreduktionsfunktionen. Am besten funktioniert das, wenn man eine Audiostelle hat, an der nur das Rauschen zu hören ist.
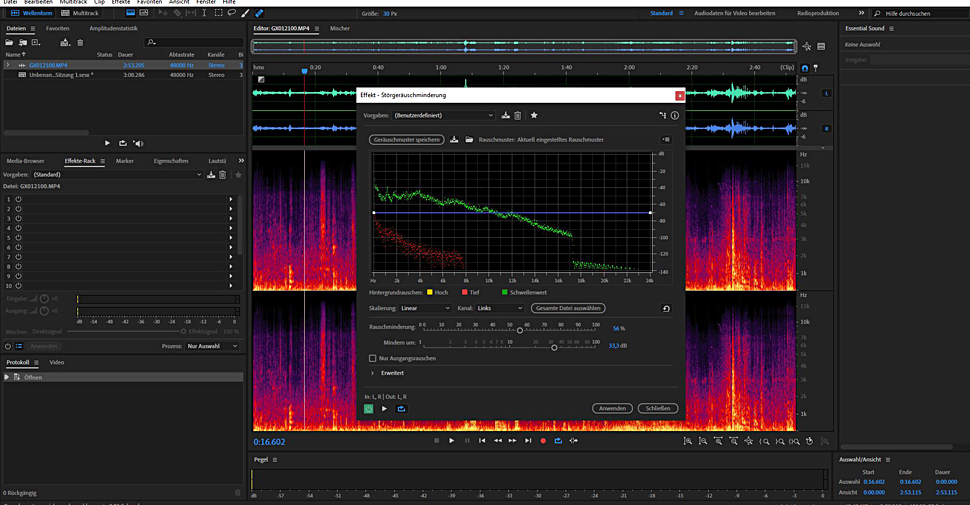
Audition filtert dann dieses Rauschen aus den Frequenzen der ganzen Audiospur heraus.
Ist Adobe Audition das Werkzeug der Wahl, dann markiert man das Rauschen und erstellt damit ein Rauschmuster. Audition filtert dann dieses Rauschen aus den Frequenzen der ganzen Audiospur heraus.
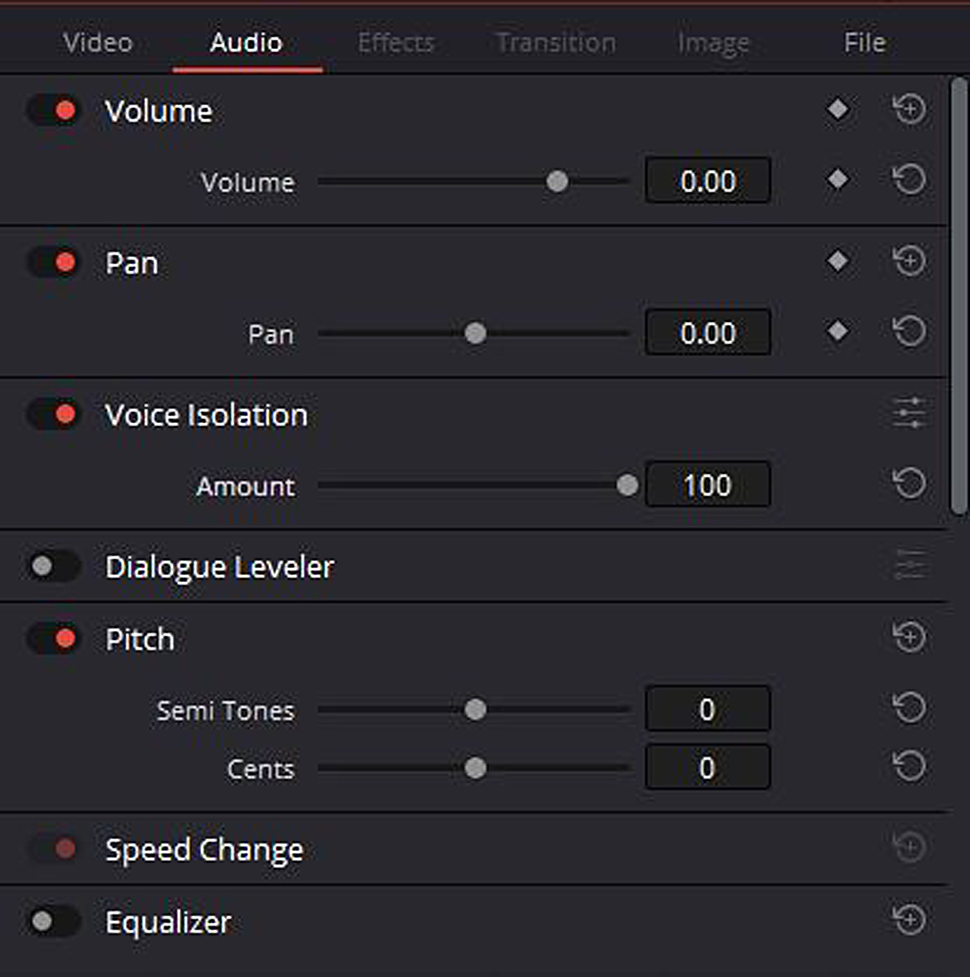
Voice Isolation in DaVinci Resolve.
KI-Funktionen, die in diesem Bereich arbeiten, können hingegen genau andersherum vorgehen: Durch Deep Learning wissen und schlussfolgern sie, wie sich verschiedene menschliche Stimmen anhören. Also isolieren sie nur die Stimme und werfen alles andere raus. Damit werden auf einen Schlag nicht nur das Rauschen, sondern auch Vogelgezwitscher, Verkehrslärm und vieles weitere eliminiert. So wird dann etwa auch der Nachhall drastisch reduziert. Es gibt dabei dann nur einen ganz einfachen Schieberegler, mit dem man die Stärke der Isolation ändern kann, um sich somit doch noch etwas von den Hintergrundgeräuschen zu bewahren, damit das nicht zu steril und unrealistisch klingt.
Meine Bewertung: Die KI in DaVinci Resolve funktioniert in puncto Stimmisolation schon ganz gut, man sollte aber auch keine Wunder erwarten.
Das gilt meiner Erfahrung nach letztlich bei allen KI-Hilfen: Hinterher akribisch kontrollieren, reinhören — und entsprechend bei Videofunktionen auch mal Einzelbilder anschauen und reinzoomen.
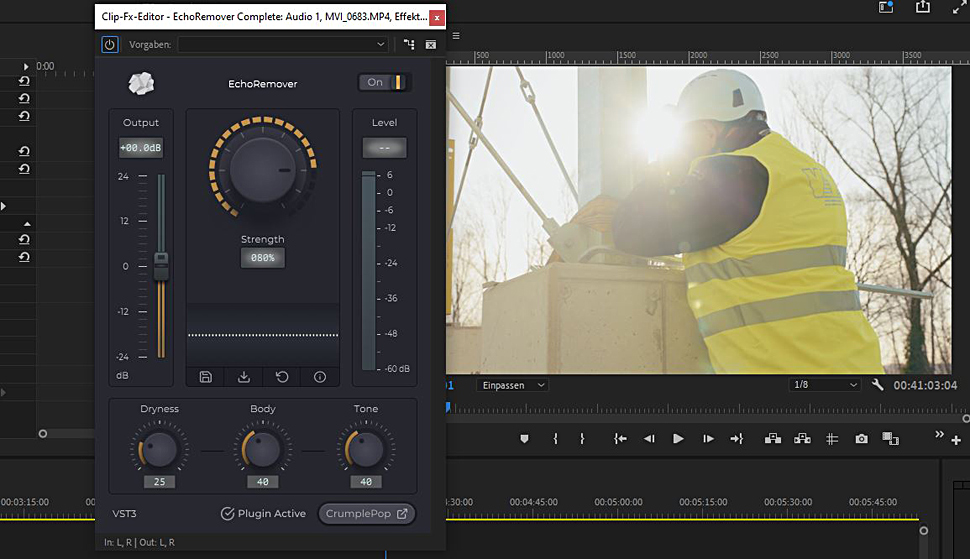
Das Plug-In EchoRemover von CrumblePop.
Zurück zum Ton: Mit Hall kommt etwa auch das Plug-In EchoRemover von CrumblePop zurecht. Ich verwende es in Premiere. Man kann hier die Stärke einstellen, verschiedene Parameter auswählen, um das Ergebnis zu verbessern, die Lautstärke zu pegeln, und man kann sich Presets speichern. CrumblePop ist im monatlichen Abo verfügbar, man kann es also auch projektbezogen nutzen.
Hier stellt sich eine Frage: Ist CrumblePop jetzt schon ein KI-Tool, oder ist es nur ein gut programmierter Filter?
In Wahrheit ist das für den Anwender letztlich schwer zu beurteilen. Hier kommt man in einen Grenzbereich, wo die meisten wohl pragmatisch agieren werden: Wenn es funktioniert, werde ich es nutzen, wenn nicht, dann eben nicht. Ist es eine KI? Who cares?
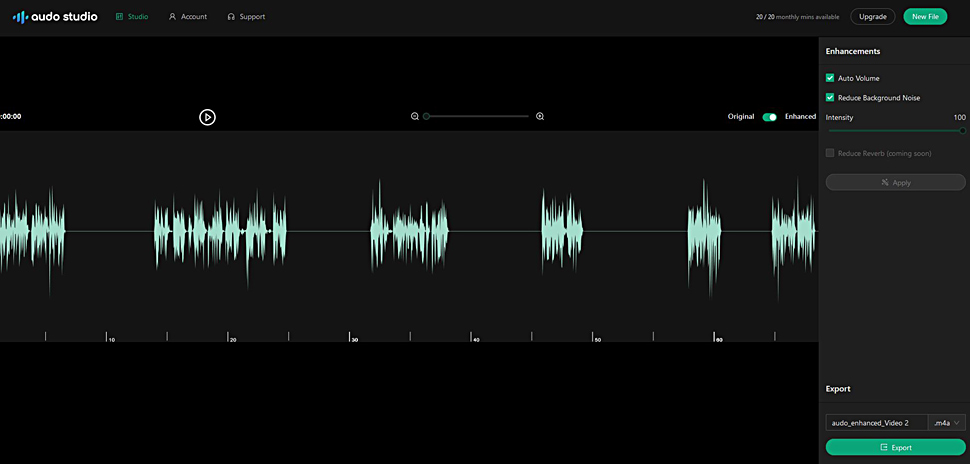
Audo Studio Online.
Außerdem gibt es noch einige andere Online-KIs, bei denen man seine Audio-Files hochladen kann, um sie dort bereinigen zu lassen. So habe ich schon gute Erfahrungen mit Audo Studio Online gemacht, das kostenlos genutzt werden kann.
Um auf die anfangs erwähnte Aktualität von Artikeln über KI zurückzukommen – ich könnte jetzt natürlich die genannten oder andere Tools beschreiben oder empfehlen… Das kann ich mir aber sparen, denn Adobe hat inzwischen mit Adobe Podcast schon wieder mal alles auf den Kopf gestellt.
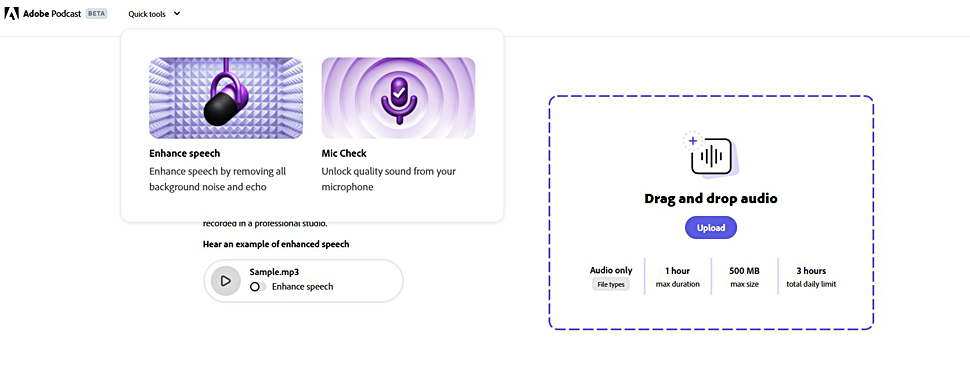
Auf Adobe Podcast kommt man über »Quick Tools« auf »Enhanced Speech«.
Hier lädt man seine Audio-Files mit maximal einer Stunde Länge hoch, um sie dann online bearbeiten zu lassen. Auf dieser Seite kommt man über »Quick Tools« auf »Enhanced Speech«. Man muss lediglich einen Account bei Adobe besitzen.
Ich habe dazu ein einfaches Praxisbeispiel: Für einen Webcast musste ich mehrere Stunden an Material schneiden und aufhübschen. Da war von Material von einer FX7 über PTZ-Kameras bis hin zu (live) Messenger-Aufnahmen vom Laptop — auch mit dementsprechend schlechter Sound-Qualität — einfach alles dabei.
Ich habe einfach nach dem Schnitt jeweils die komplette Audiospur exportiert, in Adobe Podcast hochgeladen und mich dann entspannt zurückgelehnt. Was ich dann zu hören bekam, hat bei mir seit langem mal wieder einen »Oha«-Effekt hervorgerufen. Jedes Gespräch, das auch nur ansatzweise mit einem einigermaßen guten Mikrofon aufgenommen wurde, hatte eine unglaublich gute Qualität. Und selbst viele der Messenger-Live-Aufnahmen mit den typischen digitalen Störgeräuschen waren durchaus brauchbar.
Aber auch hier kommt die weiter oben erwähnte Kontrolle wieder ins Spiel: Überlappen sich Stimmen oder sind die Störgeräusche zu heftig, kommt auch Adobes Podcast an seine Grenzen. Interessant ist der Umgang mit Hall bei Podcast. Er wird nicht komplett eliminiert, sondern auf ein Maß heruntergefahren, das natürlich und nicht störend wirkt. Will man den Hall ganz entfernen, ist CrumblePop eine gute Hilfe.
Hier habe ich im Vorfeld dann alles dafür getan, um ein möglichst verständliches Ausgangsmaterial zu haben. Dies beinhaltete unter anderem, möglichst alles gleichmäßig auszupegeln und manchmal auch manuell über Keyframes nachzuhelfen. Das bereinigte Audio habe ich dann als WAV heruntergeladen und einfach über die originale Audiospur gelegt. So kann man bei Bedarf das unbereinigte Audio noch etwas durchschimmern lassen, um Atmosphäre zu schaffen.
Gerade was Tonoptimierung angeht, bin ich voll von KI-Funktionalität überzeugt. Werde ich also jetzt nur noch mein iPhone verwenden, um Ton aufzunehmen? Mitnichten: Ein von vornherein besserer Ton ist in jedem Fall noch besser und verursacht weniger Arbeit. Aber KIs sind hier eben mein Airbag.
Ich denke, jeder, der selbst Videos produziert, hatte schon mal Videos zu bearbeiten, bei denen der Ton einfach nicht gut war, hallte oder irgendetwas im Hintergrund störte. Bei solchen Problemfällen führt zumindest im Audiobereich mittlerweile mein erster Weg zur Künstlichen Intelligenz, wenn es schnell und (fast) gut sein soll.
Bevor ich nun den Audio-Abschnitt mit Speech-to-Text abschließe, möchte ich noch kurz auf Text-to-Speech eingehen.
Da KIs zumindest auf Stufe 2 noch nichts von Emotionen verstehen, wird dies allerdings relativ kurz: Eine menschliche Sprecherin oder ein Sprecher ist aus meiner Sicht unersetzbar.
Für Spielereien oder quick und dirty Instagram-Videos könnte man eventuell mal darüber nachdenken. Hier ein eigenes Beispiel. Bei diesem Video wurden Sprechertext, Hashtags und Beschreibung bei Instagram rein per KI erledigt.
Eine Online-Service für Text-to-Speech: PlayHT.
Die Seite PlayHT bietet diverse Text-to-Voice-Generatoren und kann auch deutsch (Beispiel). Einige der deutschen Stimmen klingen sogar ganz passabel, einige englischsprachige Stimmen sind sogar recht gut. Man kann hier 5.000 Wörter im Monat unkommerziell nutzen. Ganz praktisch, um mal herumzuspielen. So fragwürdige Dinge wie Voice-Cloning kann man dort übrigens ebenfalls ausprobieren.

Was 2017 noch separate Produkte waren, gibt es heute schon als Teilaspekt von Premiere und DaVinci Resolve.
In der anderen Richtung zu arbeiten, also Speech-to-Text mit KI-Unterstützung zu nutzen, das bieten derzeit schon DaVinci Resolve und Premiere an.

Text-based Editing von Adobe bei der NAB2023.
Das Transkribieren von Text gibt es zumindest bei Adobe ja schon länger, mit Künstlicher Intelligenz ist die ganze Sache jetzt endlich auch wirklich praktisch und gut nutzbar. Ein Video zu transkribieren, bringt mehrere Vorteile mit sich: Ich kann automatische Untertitel erstellen, bei denen zudem auch automatisch »Ähs« und Ähnliches weggeschnitten werden. Diese können in die Untertitelspur gelegt oder als Datei für Youtube exportiert werden.
Interviews lassen sich jetzt auch einfach am Text orientiert schneiden – dort wo ich im Transkript den Schnitt setze, wird er auch im Video gesetzt.
Und ich kann im transkribierten B-Material einfach nach einem Schnittbild suchen, indem ich den Text eingebe, der an der Stelle gesprochen wird. Das beschleunigt unkreative Arbeiten ganz massiv.
Seite 1: KI-Grundlagen
Seite 2: Audio
Seite 3: Foto, Video
Seite 4: Live, Archiv, Fazit




Anzeige






Anzeige

Anzeige

Anzeige

Anzeige
