

Auch in diesem Jahr spielte KI bei der Anga Com eine wichtige Rolle.
Inzwischen ist KI richtig angekommen und es geht nicht mehr darum, ob sie hier oder dort zum Einsatz kommt, sondern darum, inwieweit diese in den Produktions-Alltag integriert ist und darum welche »Nebenwirkungen« zu beobachten und zu beachten sind.
Alle, die »Content« produzieren, müssen sich nicht nur Sorgen machen, dass dieser »Content« übers Internet verbreitet wird, ohne dass dafür entsprechende Vergütungen fließen, sondern auch, dass er verwendet wird, um KI zu trainieren.
Medien- und Urheberrecht bei KI
Im Panel »Medien- und Urheberrecht: Künstliche Intelligenz, Embedding und Weitersendung« setzte sich Dr. Dieter Frey in seinem Beitrag »KI und Urheberrecht – Neues Betätigungsfeld für Verwertungsgesellschaften?« mit rechtlichen Aspekten der KI auseinander.

In der Veranstaltung »Medien- und Urheberrecht: Künstliche Intelligenz, Embedding und Weitersendung«, gab es drei einzelne Vorträge.
»Die Trainingsdaten sind unbedingt notwendig, um neuronale Netzwerke zu trainieren und am Ende KI-Output zu generieren.«, sagt Frey. Dazu müsse zwischen KI-Input und KI-Output differenziert werden. In diesem Zusammenhang müssen die Regeln des im »144 Seiten feinstes, kleinbeschriebenes Amtsblatt der EU« – es ist seit August 2024 in Kraft – beachtet werden.
Um es verständlicher zu machen, greift Frey zum Bild eines Autos. Darin ist der Anbieter des KI-Modells der Motor in der KI-Welt, die KI-Systeme – also die Umsetzung – sind das Auto und der KI-Betreiber der Halter, der verantwortlich ist. Diese Strukturen werden von den Verwertungsgesellschaften aber nach Freys Meinung nicht unbedingt aufgegriffen, was aber vielleicht sinnvoll wäre.

Dr. Freys Vergleich mit einem Auto, macht verständlicher, wie KI funktioniert.
Die genannte KI-Verordnung enthält keine spezifischen Urheber- oder vergütungsrelevanten Regelungen, aber eine Verpflichtung der Anbieter von KI-Modellen, eine »hinreichend detaillierte Zusammenfassung« verwendeter Trainingsdaten zu veröffentlichen. Außerdem gibt es die Verpflichtung, eine Strategie zur Einhaltung des EU-Urheberrechts zu entwickeln. Dies gilt auch für Anbieter, die nicht in der EU sitzen.
Zurück zu KI-Input: Dass die Inhalte von Filmen, Musik und Bildern urheberrechtlich geschützt seien, sei klar, es gehe um die »Vervielfältigung« dieser Inhalte beim KI-Training. Um diese für das Training zu verwenden, »braucht man entweder eine Erlaubnis oder eine gesetzliche Schranke muss greifen, um Urheberrechte nicht zu verletzen.« Die Erlaubnis kann man einholen oder auf die Text- und Data-Mining-Schranke der EU setzen. Bei dieser geht es »darum, dass ich Inhalte kostenfrei nutzen darf, wenn sie dazu dienen, Informationsgewinn zu realisieren«, wenn der Datenschutzberechtigte nicht den Nutzungsvorbehalt erklärt, um die Schranke wieder aufzuheben. So das System in Europa, in den USA wird »Fair Use« diskutiert, was jedoch zu vielen Rechtstreitigkeiten führt.
Der Output, den die KI generiert, ist nicht urheberrechtlich geschützt. »Problematisch ist es aber dann, wenn im Output Inhalte, die von Menschen geschaffen wurden, perpetuiert werden, wenn also bestehende Werke plötzlich erkennbar sind und die KI solche Werke wiedererkennbar in Bezug nimmt.« An diesem Punkt setzen auch die Verwertungsgesellschaften an, Rechtsstreitigkeiten sind vorprogrammiert. Die USA sind dabei Vorreiter, aber »Deutschland ist mittlerweile auch dabei.« Bei drei Streitigkeiten sind direkt oder indirekt die Verwertungsgesellschaften involviert.
Verwertungsgesellschaften und KI
Die Verwertungsgesellschaften sind die Treuhänder der Urheber-Leistungsschutzverhältnisse. Bei Massengeschäften bündeln sie die Rechte und vermarkten sie. Dazu schließen sie sowohl mit den Urhebern als auch den Vermarktern Verträge ab.
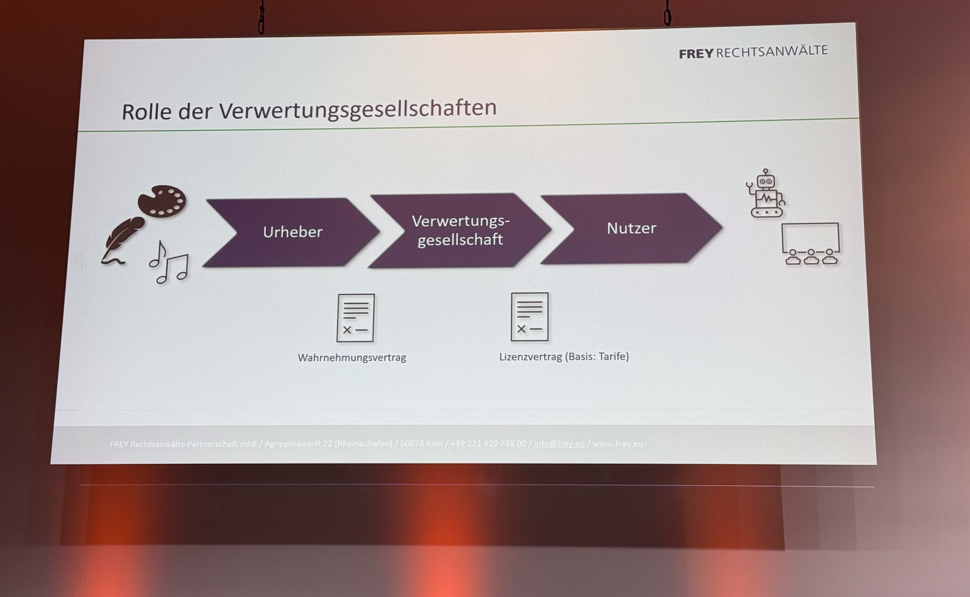
Übersicht zur Rolle der Verwertungsgesellschaften.
Bei der KI schauen sie sowohl auf den KI-Input als auch den KI-Output in der Absicht, um neue Vergütungsströme für die Wahrnehmungsberechtigten zur erschließen. Dazu führen sie auch Rechtsstreitigkeiten oder finanzieren diese, wie beispielsweise die VG Bild-Kunst. »Sie finanziert zumindest die Berufung des ersten deutschen KI-basierten Rechtsstreites«, dieser läuft in Hamburg. Außerdem passt sie die Wahrnehmungsverträge an und möchte dabei auch den Rechtevorbehalt, um das Verbot zum Text- und Data-Mining aussprechen zu können. Ein Verbot gibt es aber bislang nicht.
Bei der VG Wort wurden und werden die Wahrnehmungsverträge angepasst, Rechtsstreitigkeiten gibt es bislang keine. »Sie ist allerdings der Auffassung, dass die Text- und Data-Mining-Schranke im Hinblick auf das KI-Training keine Anwendung findet.« Einen Tarif zur Nutzung gibt es inzwischen.
Die Gema führt zwei Rechtsstreitigkeiten, einen gegen Open AI und einen weiteren gegen den Musikgenerator Suno. Weiterhin hat sie die Wahrnehmungsverträge geändert und sich das Recht einräumen lassen, Nutzungsvorbehalte zu erklären. Zudem hat sie die Tarife angepasst und kann jetzt auch Nutzer verpflichten, den Nutzungsvorbehalt zu erklären und somit »um die Ecke« den Lizenznehmern zu verbieten, Websites mit Gema-Musik als Quelle für das Text- und Datamining zu benutzen.

Das Lizenzmodell der Gema hat zwei Säulen.
Außerdem hat die Gema die Beweislastumkehr eingeführt. Der Nutzer von Musik muss jetzt beweisen, »dass es keine urheberrechtlich geschützte Musik ist«, auch wenn es sich um KI erzeugte Musik handelt. Der Hintergrund ist, dass »die Gema der Auffassung ist, dass sich in KI-generiertem Content die urheberrechtlich geschützte Musik, die sie wahrnimmt, perpetuiert, also verlängert,« da dort noch die vorbestehenden Daten erkennbar seien. Dafür muss bezahlt werden, wenn nicht bewiesen werden kann, »dass es nichts mehr mit den vorbestehenden Daten zu tun hat.« Soweit die zweite Säule des Gema-Lizenzmodells.

Der Stand der Dinge bei den einzelnen Verwertungsgesellschaften.
Bei der ersten Säule sollen alle, die Content als Trainingsdaten nutzen, mit 30% ihres Umsatzes zur Kasse gebeten werden. »Da würde ich sagen, wir sind noch nicht am Ende mit der Diskussion und den Rechtsstreitigkeiten«, sagt Frey.
Seite 1: KI und Urheberrecht
Seite 2: KI verändert die Medienbranche









